

引言
在众多的数据集之中,2004年的天天开好彩全集是一个值得关注的资源。该数据集因其详尽而风靡一时,众多预测者、分析家以及数据爱好者纷纷对其展开深入的研究与探讨。本文旨在提供一个关于2004年天天开好彩全集的数据解释说明规划,以便相关利益方可以有效地进行数据分析和预测。
数据集介绍
本数据集涵盖了2004年每一天的彩票结果,包含了众多类型的彩票数据。数据涵盖了各个省份的开奖信息,因此在地域上的代表性非常广泛,能帮助分析者从多元角度了解彩票趋势。
数据结构和特点
在数据的结构方面,2004年天天开好彩全集采用标准的表格形式,每行代表一天的彩票结果。表格包括日期、省份、彩票类型等各种字段,便于进行分类和比较。以下是数据集中的一些关键字段:
- 日期:记录了彩票开奖的具体日期。
- 省份:表明了彩票所在的省份信息。
- 彩票类型:包括各种彩票类型,如数字型、猜谜型等。
- 开奖结果:实际开奖的数字或结果。
数据字段完整性与数据质量
数据的完整性和质量是分析结果准确性的基础,2004年天天开好彩全集的数据质量普遍较好,但使用者仍需要对数据进行适当的验证,以确保结果的可靠性。
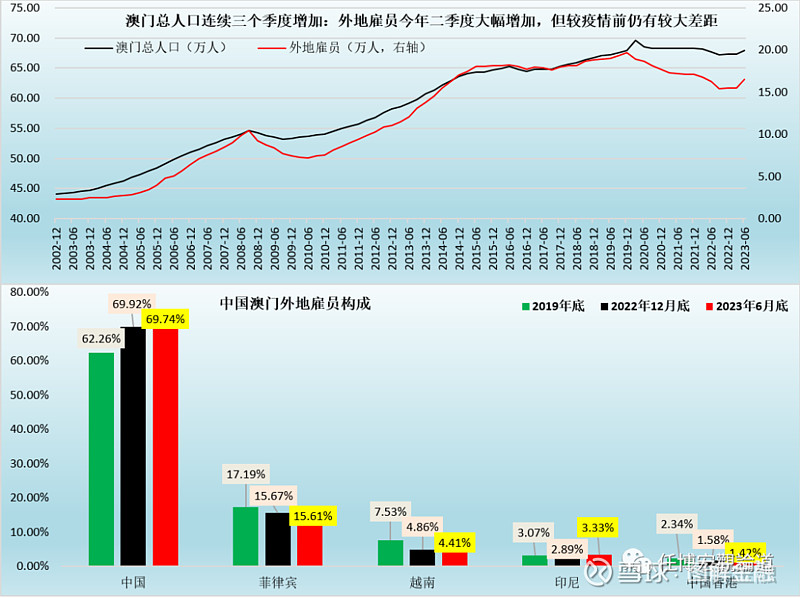
数据分析的目标和应用场景
目标
2004年天天开好彩全集的数据分析可以达成以下目标:
- 趋势预测:通过挖掘历史数据中的模式,预测未来的彩票结果。
- 市场分析:了解不同地区和不同类型的彩票的市场动态。
- 风险评估:评估参与彩票投资的风险与收益比。
应用场景
- 彩票公司:彩票公司可以利用这些数据来预测市场趋势,制定更加有效的营销策略。
- 投资者:对于有意图涉足彩票市场的投资者来说,分析这些数据有助于他们进行风险评估和投资决策。
- 政策制定者:对于政府和政策制定者而言,了解彩票市场的趋势和问题有助于制定更加合理的管理政策。
数据解释说明规划
数据清洗
数据清洗是任何数据分析流程的第一步。2004年天天开好彩全集的数据虽然质量较高,但进行初步的数据清洗仍然是必要的。这包括:
- 去除异常值:识别并排除数据中的异常或错误的记录。
- 缺失值处理:对于缺失的数据,需要决定是删除、填充还是通过模型估计这些值。
数据理解
理解数据是进行有效数据分析的前提。我们需要对数据集中的每个字段及其含义有所了解。例如:

- 日期字段:了解数据集中的日期范围,以及该范围内可能影响彩票结果的外部因素。
- 彩票类型字段:认识每种彩票类型的特点,并区分不同彩票的开奖结果。
数据可视化
数据可视化能够帮助我们更直观地理解数据和发现潜在的趋势或模式。常见的可视化方法包括:
- 图表:使用柱状图、折线图或饼图来展示数据。
- 地理图表:由于数据包括省份信息,可以使用地理图表显示不同地区的彩票趋势。
数据建模
建模是数据分析中的一个核心步骤,通过建立模型来预测结果或解释数据。在2004年天天开好彩全集的分析中,可以考虑以下几种模型:
- 统计模型:根据历史数据确定概率分布,进行统计分析。
- 机器学习模型:运用机器学习技术预测未来彩票结果。
结果验证
无论建模结果如何,通过实际数据验证模型的准确性是必不可少的。在彩票数据分析中,验证模型的有效性可通过:

- 交叉验证:将数据分为训练集和测试集,通过评估测试集上的模型性能来进行验证。
- 实时监控:长期的跟踪验证模型对新数据的适应性。
结语
2004年天天开好彩全集作为一个宝贵的数据资源,为彩票市场的研究提供了平台。通过上述的数据解释说明规划,我们能够更好地理解、分析并预测彩票市场的趋势。这份规划旨在指导相关利益方如何有效利用数据,以期在数据的海洋中获得有价值的洞见。
希望这篇文章能为对2004年天天开好彩大全感兴趣并致力于相关领域研究的朋友们提供一些参考和启示。数据的力量是巨大的,正确地使用数据,我们可以预见未来的彩票市场,从而做出更为明智的决策。






 京公网安备11000000000001号
京公网安备11000000000001号 京ICP备11000001号
京ICP备11000001号
还没有评论,来说两句吧...